 Sascha Dittmann Über .NET, SQL Server und die Cloud
Sascha Dittmann Über .NET, SQL Server und die Cloud
 Meine Reise mit der Developer Preview des neuen Cloud Speicherdienstes „Apache™ Hadoop™-based Services for Windows Azure“ geht weiter:
Meine Reise mit der Developer Preview des neuen Cloud Speicherdienstes „Apache™ Hadoop™-based Services for Windows Azure“ geht weiter:
Diesmal stehen die Interaktive Konsole und ein einfacher MapReduce-Algorithmus mit JavaScript auf dem Plan.
Im meinem letzten Blog Post „Apache Hadoop Dienste für Windows Azure (Developer Preview)“ hatte ich von der Erstellung eines eigenen Hadoop Clusters berichtet.
Nachdem dieses dann einsatzbereit war, wollte ich mich auf den Weg zu ein wenig Quellcode machen.
Doch eine grundlegende Frage beschäftigte mich:
Was ist MapReduce?
Eine kurz Suche im Internet ergab, dass es sich um einen von Google entwickelten Algorithmus handelt, mit dessen Hilfe man verteile Berechnungen über große Datenmengen (im Petabyte-Bereich) durchführen kann.
Hierzu müssen eine Map- sowie eine Reduce-Funktion zur Verfügung gestellt werden.
Optional kann zusätzlich eine Combine-Funktion angegeben werden.
Die Map-Funktion
Die Map-Funktion berechnet dann, pro Knoten im Cluster, einen Teil des Gesamtergebnisses.
Die so entstehenden Zwischenergebnisse, werden in einer Liste von Schlüssel-Wert-Paaren (Key-Value-Pairs) zurückgegeben.
Die Combine-Funktion
Falls eine Combine-Funktion implementiert wurde, wird dieses auf dem gleichen Clusterknoten wie die Map-Funktion ausgeführt.
Ziel ist es hierbei die Menge der Zwischenergebnisse zu verkleinern, um die darauffolgende Netzwerkbelastung, die bei der Übertragung der Zwischenergebnisse entsteht, zu minimieren.
Die Reduce-Funktion
Wurden alle Map- und Combine-Funktionen erfolgreich durchgeführt, beginnt die Reduce-Phase.
Hierbei berechnet die Reduce-Funktion aus den Zwischenergebnismengen die Gesamtergebnismenge.
Doch wie funktioniert dies in der Praxis?
Als einfaches Beispiel möchte ich das Wörterzählen in Textdateien aufgreifen.
Die Interaktive Konsole
Zu Beginn loggte ich mich also in mein Cluster der Apache™ Hadoop™-based Services for Windows Azure ein.
Im Dashboard wählte ich anschließend die Interaktive Konsole aus:
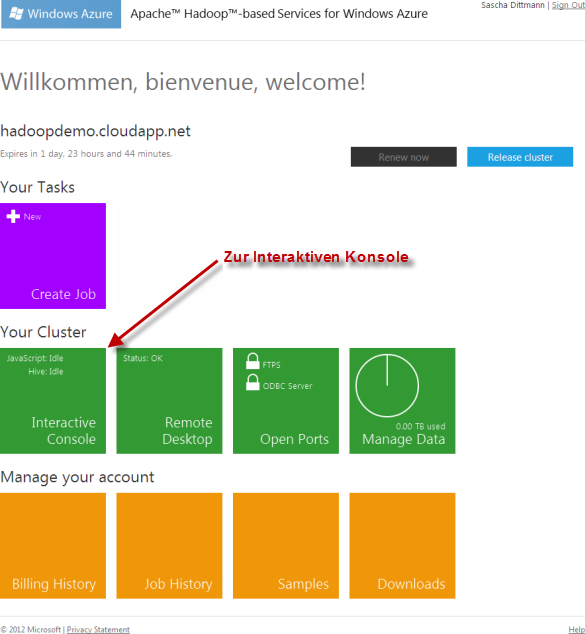
Mit der Interaktiven Konsole kann, mittels JavaScript Funktionen bzw. UNIX-ähnlichen Befehlen, auf das verteilte Dateisystem zugegriffen werden. Außerdem stehen weitere Funktionalitäten, wie z.B. das Starten von Berechnungen oder die Anzeige von einfachen Graphen, zur Verfügung.
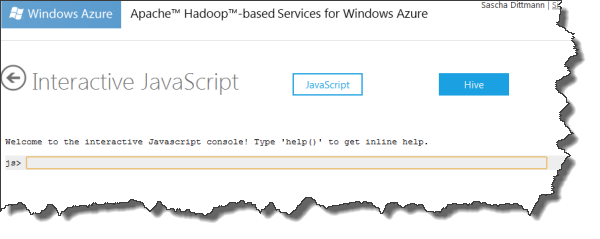
Die Vorbereitungen
Um ein wenig Text zum analysieren zu haben, bediente ich mich einiger Passagen aus Goethes Faust I.
Diese speicherte ich absatzweise in einzelne Textdateien.
In der Konsole musste ich dann nur noch ein Verzeichnis für die Texte erstellen, …
js> #mkdir texte
… sowie die einzelnen Dateien in das Hadoop Dateisystem (HDFS) hochladen.
js> fs.put() File uploaded.
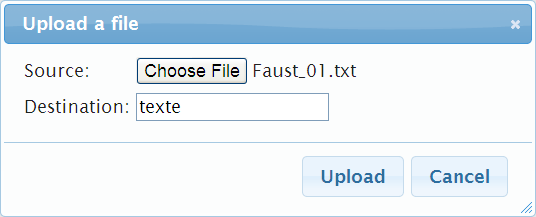
Dann noch eine kurze Kontrolle, ob alles erfolgreich in Hadoop gelandet ist …
js> #ls Found 2 items drwxr-xr-x - MyUser supergroup 0 2012-02-12 /user/MyUser/.oink drwxr-xr-x - MyUser supergroup 0 2012-02-12 /user/MyUser/texte js> #ls texte Found 17 items -rw-r--r-- 3 MyUser supergroup 366 2012-02-12 /user/MyUser/texte/Faust_01.txt -rw-r--r-- 3 MyUser supergroup 351 2012-02-12 /user/MyUser/texte/Faust_02.txt -rw-r--r-- 3 MyUser supergroup 340 2012-02-12 /user/MyUser/texte/Faust_03.txt -rw-r--r-- 3 MyUser supergroup 358 2012-02-12 /user/MyUser/texte/Faust_04.txt -rw-r--r-- 3 MyUser supergroup 1071 2012-02-12 /user/MyUser/texte/Faust_05.txt -rw-r--r-- 3 MyUser supergroup 335 2012-02-12 /user/MyUser/texte/Faust_06.txt -rw-r--r-- 3 MyUser supergroup 351 2012-02-12 /user/MyUser/texte/Faust_07.txt -rw-r--r-- 3 MyUser supergroup 581 2012-02-12 /user/MyUser/texte/Faust_08.txt -rw-r--r-- 3 MyUser supergroup 657 2012-02-12 /user/MyUser/texte/Faust_09.txt -rw-r--r-- 3 MyUser supergroup 168 2012-02-12 /user/MyUser/texte/Faust_10.txt -rw-r--r-- 3 MyUser supergroup 1054 2012-02-12 /user/MyUser/texte/Faust_11.txt -rw-r--r-- 3 MyUser supergroup 993 2012-02-12 /user/MyUser/texte/Faust_12.txt -rw-r--r-- 3 MyUser supergroup 1126 2012-02-12 /user/MyUser/texte/Faust_13.txt -rw-r--r-- 3 MyUser supergroup 487 2012-02-12 /user/MyUser/texte/Faust_14.txt -rw-r--r-- 3 MyUser supergroup 609 2012-02-12 /user/MyUser/texte/Faust_15.txt -rw-r--r-- 3 MyUser supergroup 611 2012-02-12 /user/MyUser/texte/Faust_16.txt -rw-r--r-- 3 MyUser supergroup 444 2012-02-12 /user/MyUser/texte/Faust_17.txt
… und schon konnte ich zum eigentlich Coding übergehen.
MapReduce mit JavaScript
Die Map-Funktion
Die Map-Funktion generiert für jedes Wort in der Textdatei einen Eintrag (Key-Value-Pair) und fügt diesen der Zwischenergebnismenge hinzu.
Hierzu wird ein Regulärer Ausdruck, sowie eine Schleife, benutzt.
var map = function (key, value, context)
{
var words = value.split(/[^a-zA-Z]/);
for (var i = 0; i < words.length; i++) {
if (words[i] !== "") {
context.write(words[i].toLowerCase(), 1);
}
}
};
Die Combine-Funktion
Da für jedes Wort ein Key-Value-Pair mit der Anzahl 1 erstellt wird, können diese in der Combine-Funktion bereits vorsummiert werden.
Außerdem können unerwünschte Wörter herausgefiltert werden, wie z.B. „und“, „der“, „die“, „das“, etc., da auf Grund der unterschiedlichen Häufigkeit von Wörtern in der natürlichen Sprache, bei einem deutschen Text sehr oft eine Ausgabe in der Form („und“, 1) erzeugt werden würde.
var combine = function (key, values, context) {
var sum = 0;
if (key == 'und'
|| key == 'der'
|| key == 'die'
|| key == 'das') return;
while (values.hasNext()) {
sum += parseInt(values.next());
}
context.write(key, sum);
};
Die Reduce-Funktion
Identisch zur Combine-Funktion, werden bei der Reduce-Funktion die Zwischenergebnisse aufsummiert, um die Gesamtsummen aller Textdateien zu erhalten.
var reduce = function (key, values, context) {
var sum = 0;
while (values.hasNext()) {
sum += parseInt(values.next());
}
context.write(key, sum);
};
JavaScript Funktionen ausführen
Die nun definierten Funktionen können auf unterschiedliche Arten ausgeführt werden:
Direkt
Die erste Möglichkeit, die ich hierbei vorstellen möchte, benötigt in der hochgeladenen JavaScript Datei eine Funktion, die als Hauptprogramm dient.
Dies könnte in unserem Beispiel wie folgt aussehen:
var main = function (factory) {
var job = factory.createJob("woerterZaehlen", "map", "reduce");
job.setCombiner("combine");
job.waitForCompletion(true);
};
Anschließend kann man das Ganze, unter Angabe der JavaScript Datei, sowie einem Quell- und Zielverzeichnis, starten:
js> #ls
Found 3 items
drwxr-xr-x - MyUser supergroup 0 2012-02-13 13:40 /user/MyUser/.oink
-rw-r--r-- 3 MyUser supergroup 661 2012-02-13 16:52 /user/MyUser/WordCount.js
drwxr-xr-x - MyUser supergroup 0 2012-02-13 15:10 /user/MyUser/texte
js> runJs("WordCount.js", "texte", "woerter")
View Log
Mit Pig verfeinern
Eine weitere Möglichkeit stellt das Einbetten in Apache Pig dar.
Hierbei kann der Output-Stream des eingebetteten MapReduce-Algorithmus, mittels des Pig Latin Syntax, weiter verfeinert werden.
js> pig.from("texte").mapReduce("WordCount.js", "word, count:long")
.orderBy("count DESC").take(15).to("Top15Woerter")
View Log
Im hier gezeigten Beispiel wird nach „count“ sortiert und nur die ersten 15 Schlüssel/Wert-Paare im Output-Stream gespeichert.
Die Live-Ansicht des Protokolls, kann über den Link „View Log“ angezeigt werden.
Ergebnisse Anzeigen
Nachdem der MapReduce-Job erfolgreich beendet wurde, kann die Ergebnismenge mit folgendem Befehl angezeigt werden (inkl. Objektreferent zur weiteren Verarbeitung):
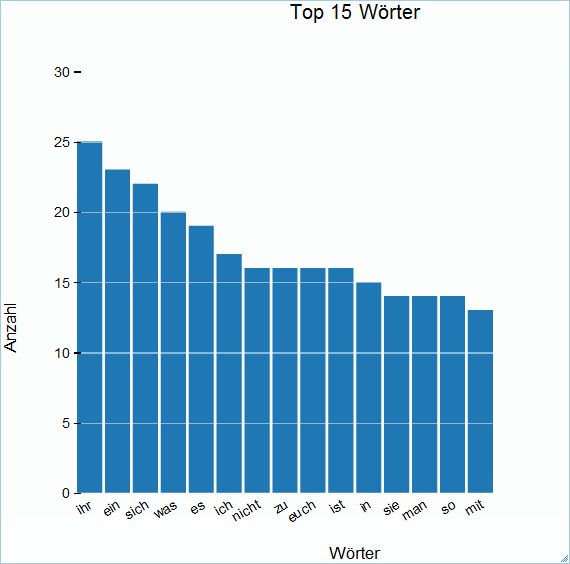
js> ergebnisse = fs.read("Top15Woerter")
ihr 25
ein 23
sich 22
was 20
es 19
ich 17
nicht 16
zu 16
euch 16
ist 16
in 15
sie 14
man 14
so 14
mit 13
Diese Ergebnismenge kann anschließend, mit Hilfe der o.g. Objektreferenz, in ein JSON-Objekt umgewandelt, …
js> daten = parse(ergebnisse.data,"Wörter, Anzahl:long")
[
0: {
Wörter: "ihr"
Anzahl: 25
}
1: {
Wörter: "ein"
Anzahl: 23
}
2: {
Wörter: "sich"
Anzahl: 22
}
3: {
Wörter: "was"
Anzahl: 20
}
4: {
Wörter: "es"
Anzahl: 19
}
5: {
Wörter: "ich"
Anzahl: 17
}
6: {
Wörter: "nicht"
Anzahl: 16
}
7: {
Wörter: "zu"
Anzahl: 16
}
8: {
Wörter: "euch"
Anzahl: 16
}
9: {
Wörter: "ist"
Anzahl: 16
}
10: {
Wörter: "in"
Anzahl: 15
}
11: {
Wörter: "sie"
Anzahl: 14
}
12: {
Wörter: "man"
Anzahl: 14
}
13: {
Wörter: "so"
Anzahl: 14
}
14: {
Wörter: "mit"
Anzahl: 13
}
]
sowie als Balkengrafik angezeigt werden.
js> metadaten = { title: "Top 15 Wörter", orientation: 30, x: "Wörter", y: "Anzahl" }
{
title: "Top 15 Wörter"
orientation: 30
x: "Wörter"
y: "Anzahl"
}
js> graph.bar(daten, metadaten)

very good example for beginers to work with hadoop using javascript