 Sascha Dittmann Über .NET, SQL Server und die Cloud
Sascha Dittmann Über .NET, SQL Server und die Cloud
 Am Montag hatte ich bereits aufgezeigt, wie man ein Storage Account, den Cloud Service, sowie das Virtuelle Netzwerk für ein manuell erstelltes Hadoop on Linux Cluster anlegt.
Am Montag hatte ich bereits aufgezeigt, wie man ein Storage Account, den Cloud Service, sowie das Virtuelle Netzwerk für ein manuell erstelltes Hadoop on Linux Cluster anlegt.
In diesem Teil meiner dreiteiligen Serie stelle ich vor, wie man ein Basis-Image für die Cluster-Knoten erstellen kann…
Da das Ganze für einen einzelnen Blog Post etwas zu umfangreich ausfallen würde, habe ich diese Step-By-Step Anleitung in 3 Teile aufgesplittet:
-
Vorbereitung der Azure Umgebung
(Storage Account, Cloud Service und Virtuelles Netzwerk) - Erstellen eines Basis-Images
- Erzeugen des Clusters
Virtuelle Maschine Erstellen
 Da ich natürlich nicht komplett bei Null anfangen möchte, nutze ich als Basis für unsere Hadoop on Linux Vorlage ein CentOS 6.x Image aus der Azure VM Gallery.
Da ich natürlich nicht komplett bei Null anfangen möchte, nutze ich als Basis für unsere Hadoop on Linux Vorlage ein CentOS 6.x Image aus der Azure VM Gallery.
Für die neue Virtuelle Maschine wähle ich deshalb New -> Compute -> Virtual Machine -> From Gallery aus.
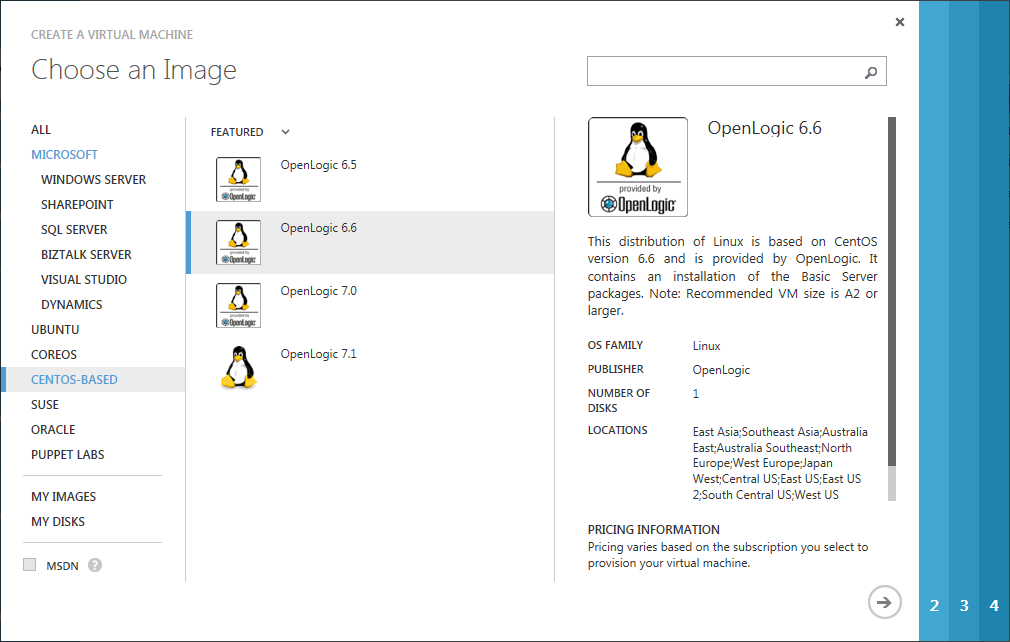 Im ersten Schitt des Assistenten-Dialogs wählen ich dann entsprechend die aktuellste OpenLogic 6.x Vorlage aus.
Im ersten Schitt des Assistenten-Dialogs wählen ich dann entsprechend die aktuellste OpenLogic 6.x Vorlage aus.
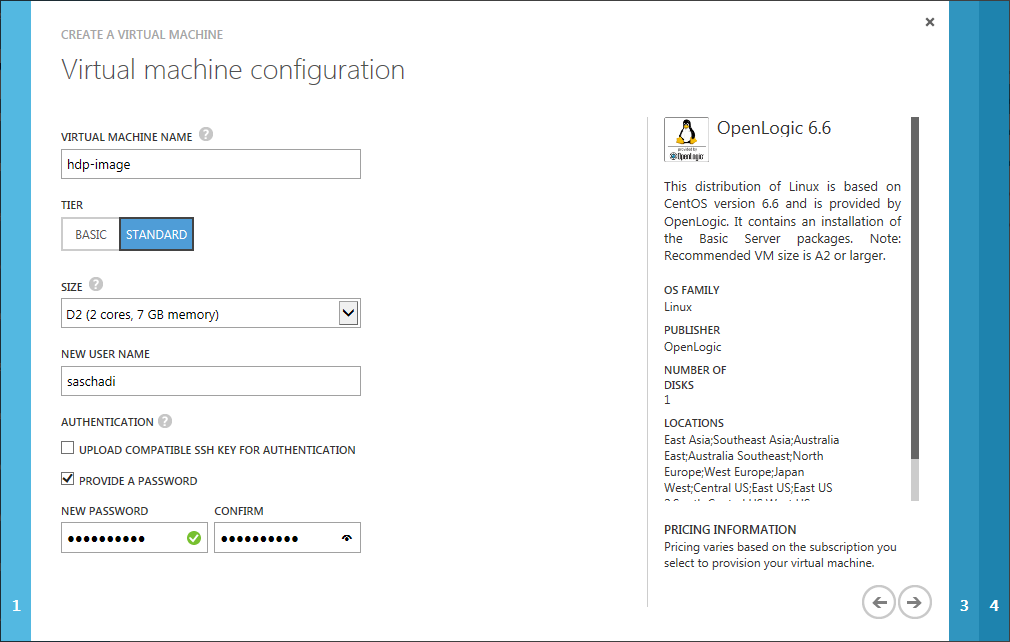 Im zweiten Schritt muss ich Angaben zur Virtuellen Maschine machen.
Im zweiten Schritt muss ich Angaben zur Virtuellen Maschine machen.
Hier verpasse ich der Maschine den Namen »hdp-image«, da diese ohnehin am Ende des Prozesses in ein Basis-Image umgewandelt wird.
Ausserdem wähle ich die VM-Größe »Standard_D2« aus.
Im Gegensatz zur A-Serie der Azure VMs, haben die Maschinen der D-Serie besonders viel Arbeitsspeicher und eine lokale SSD, die für das Temporäre Laufwerk genutzt wird.
Für das Administratorkonto muss ich noch einen Benutzernamen und Passwort angeben.
Ein Zertifikat für die Secure Shell (SSH) möchte ich nicht benutzen.
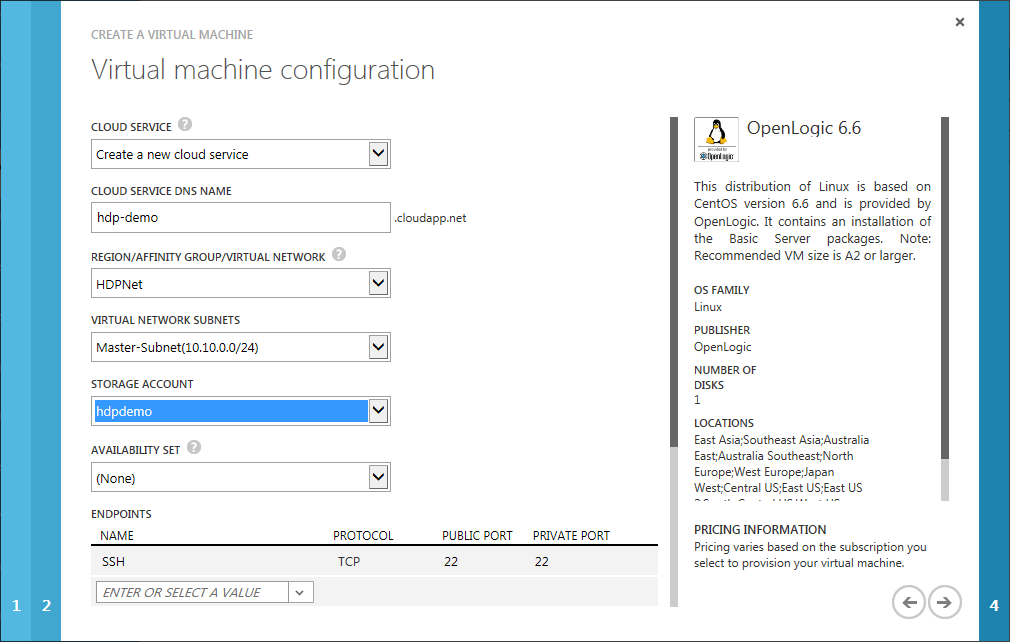 In Schritt 3 werden der Cloud Service, das Virtuellen Netzwerk, das Subnetz und das Storage Account ausgewählt, die ich im ersten Teil dieser Step-By-Step Anleitung erstellt hatte.
In Schritt 3 werden der Cloud Service, das Virtuellen Netzwerk, das Subnetz und das Storage Account ausgewählt, die ich im ersten Teil dieser Step-By-Step Anleitung erstellt hatte.
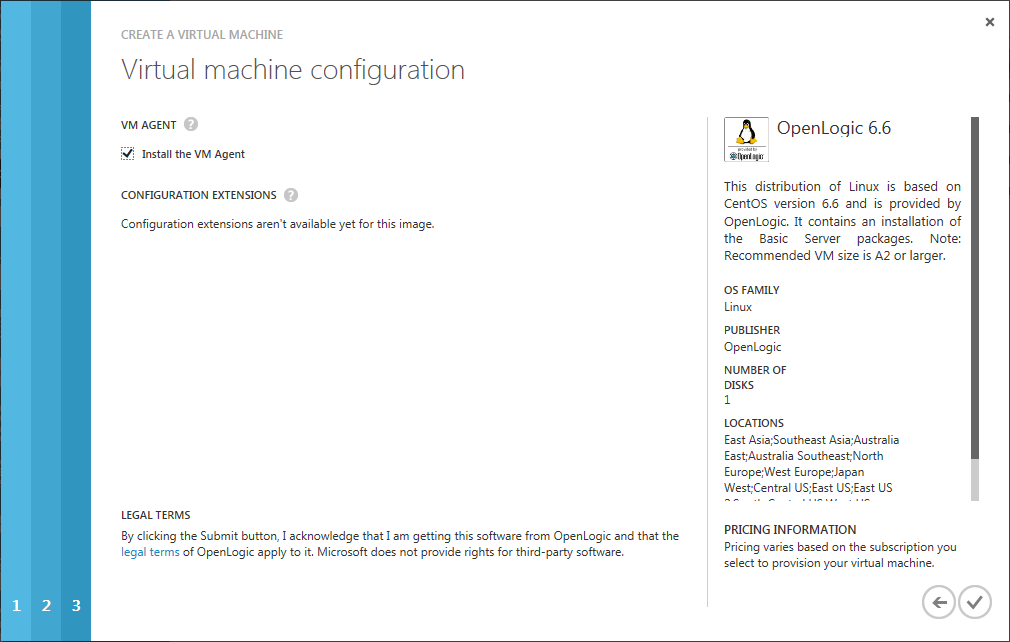 Als Erweiterung für Azure VMs, sollte noch der VM Agent installiert werden.
Als Erweiterung für Azure VMs, sollte noch der VM Agent installiert werden.
Dieser wird am Ende dieses Prozesses genutzt, um die VM für die Image-Erstellung vorzubereiten.
Aktualisieren des Betriebssystems
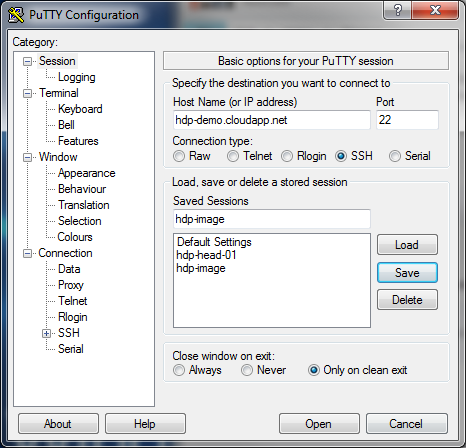
Damit die Virtuelle Maschine für unsere Zwecke angepasst werden kann, muss man sich als erstes eine Secure Shell (SSH) Verbindung herstellen.
SSH ist auf Unix-Betriebssystemen und OS X meist vorinstalliert.
Für Windows-Systeme kann das kostenlose Tool PuTTY genutzt werden.
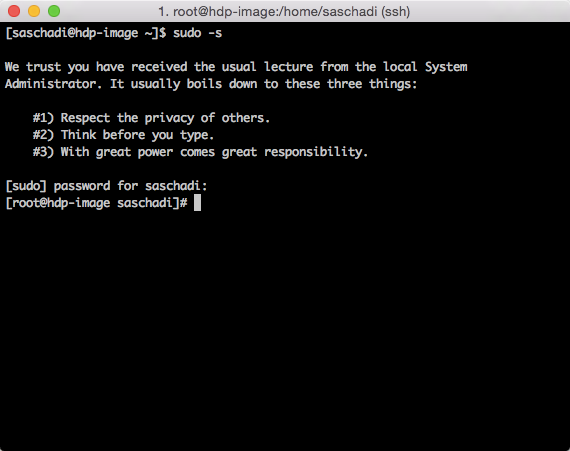 Anschließend sollte man die Session mit »sudo -s« dauerhaft in den Administrator-Modus heben, da man ansonsten vor jedem der folgenden Befehle separat »sudo« voranstellen müsste.
Anschließend sollte man die Session mit »sudo -s« dauerhaft in den Administrator-Modus heben, da man ansonsten vor jedem der folgenden Befehle separat »sudo« voranstellen müsste.
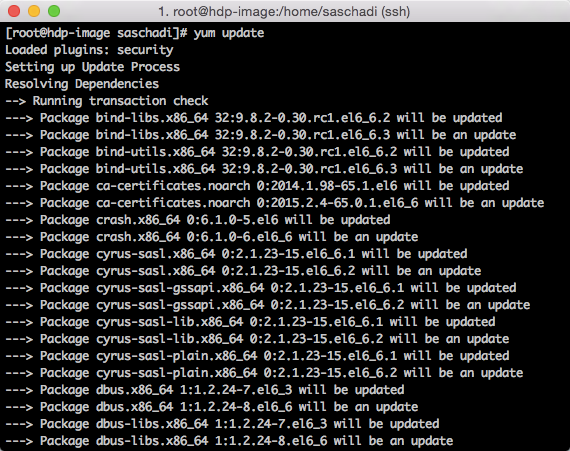 Um alle installierten Pakete des Betriebsystems auf den aktuellen Stand zu bringen, führe ich als erstes den Befehl »yum update« aus.
Um alle installierten Pakete des Betriebsystems auf den aktuellen Stand zu bringen, führe ich als erstes den Befehl »yum update« aus.
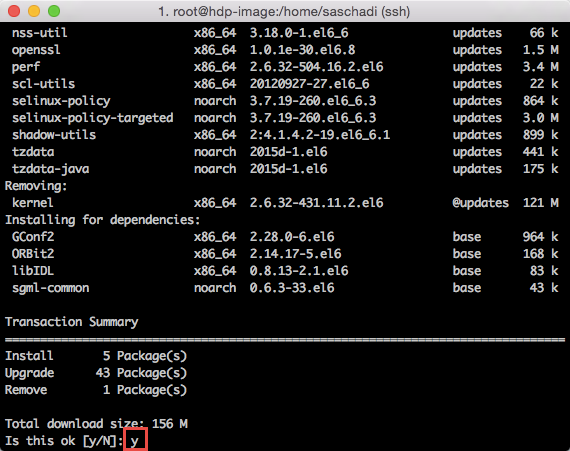 Nach dessen initialer Prüfung, muss der Download zuvor noch mit einem »y« bestätigt werden.
Nach dessen initialer Prüfung, muss der Download zuvor noch mit einem »y« bestätigt werden.
Passwortloses SSH
Damit später das Hadoop Installations- und Verwaltungssystem Ambari eine Administratorverbindung zu den einzelnen Knoten herstellen kann, muss vorher das Passwortlose SSH eingerichtet werden.
Hierzu muss zuerst ein RSA-Schlüsselpaar erstellt werden.
Anschließend wird dieses als Autorisiertes Schlüsselpaar für das Basis-Image (und dementsprechend für alle später erstellten Knoten) bekannt gemacht und die entsprechenden Dateisystemrechte gesetzt:
ssh-keygen cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys chmod 700 ~/.ssh chmod 600 ~/.ssh/*
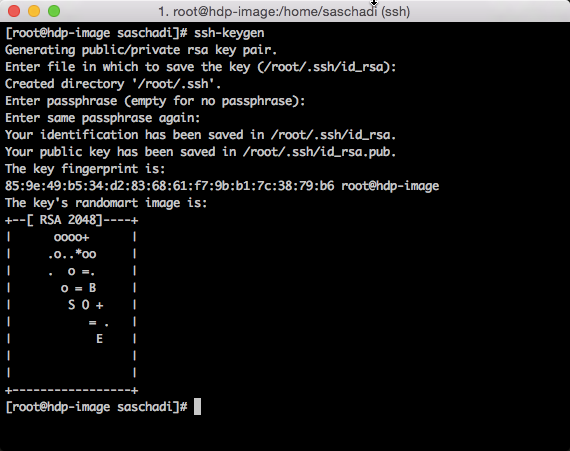
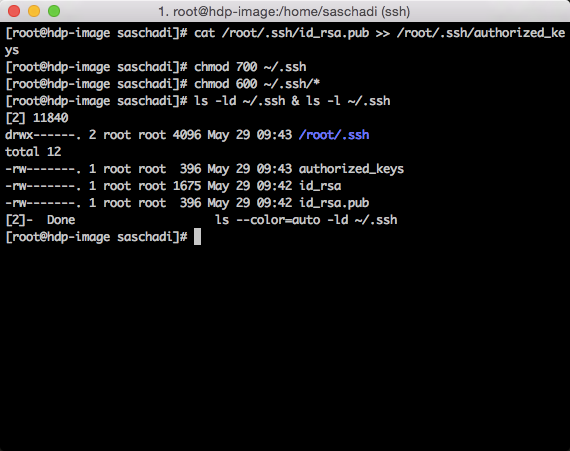
Mit »ls -ld ~/.ssh & ls -l ~/.ssh« lassen sich die vorgenommenen Einstellungen nochmals prüfen.
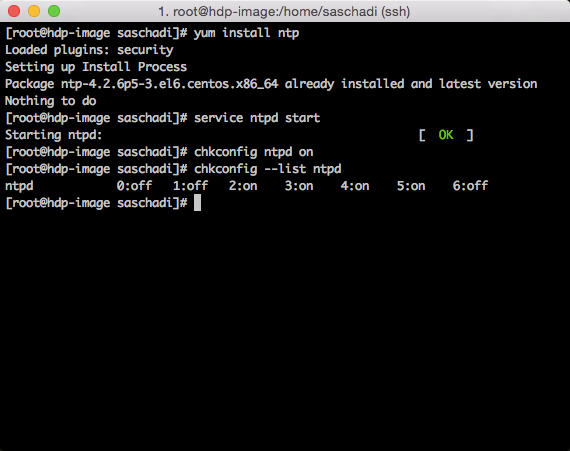
Network Time Protocol (NTP)
Damit später auch alle Cluster-Knoten im "Gleichen Takt" ticken, muss der Network Time Protocol (NTP) Dienst installiert und aktiviert werden.
Geprüft werden kann die Installation mit »chkconfig –list ntpd«.
yum install ntp service ntpd start chkconfig ntpd on
SELinux Deaktivieren
Da sich die Security-Enhanced Linux (kurz SELinux) Kernel-Erweiterung mit Ambari beißt, muss diese deaktiviert werden.
Hierzu führt man folgenden Befehl aus:
setenforce 0
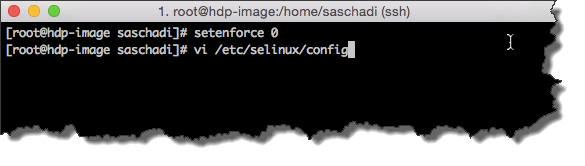
Damit diese auch nach dem Neustart der VMs nicht wieder aktiv wird, muss man die entsprechende Konfigurationsdatei (/etc/selinux/config) angepasst werden.
Dabei muss »SELINUX« auf »disabled« gesetzt werden.
vi /etc/selinux/config
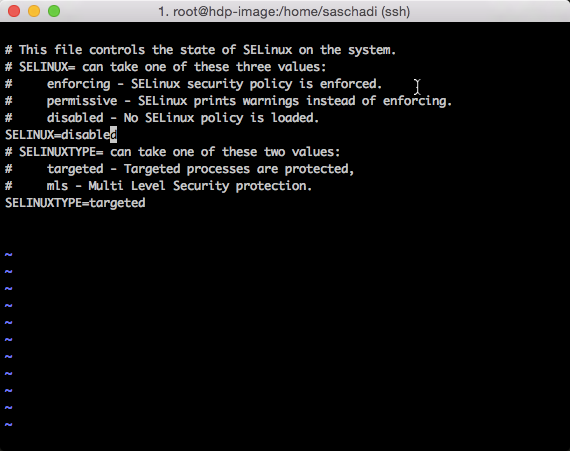
PackageKit Deaktivieren
Auch das PackageKit kann zu Problemen führen, weshalb dies deaktiviert werden sollte.
Hierzu muss »enabled=0« in der entsprechenden Konfigurationsdatei (/etc/yum/pluginconf.d/refresh-packagekit.conf) gesetzt werden.
vi /etc/yum/pluginconf.d/refresh-packagekit.conf
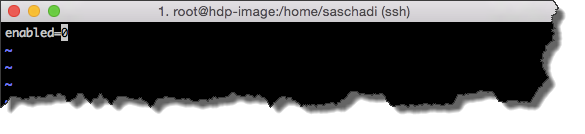
Da diese in der aktuellen Vorlage der Azure VM Gallery nicht vorhanden ist, kann auch folgender Befehl genutzt werden.
echo 'enabled=0' >> /etc/yum/pluginconf.d/refresh-packagekit.conf
Transparent Huge Pages (THP) Deaktivieren
Um etwaigen Performance-Problemen aus dem Weg zu gehen, sollten auch die Transparent Huge Pages (THP) abgeschaltet werden.
Dieser Mechanismus ist ähnlich der Windows-Auslagerungsdatei (pagefile.sys) und lagert Daten des virtuellen Speichers aus.
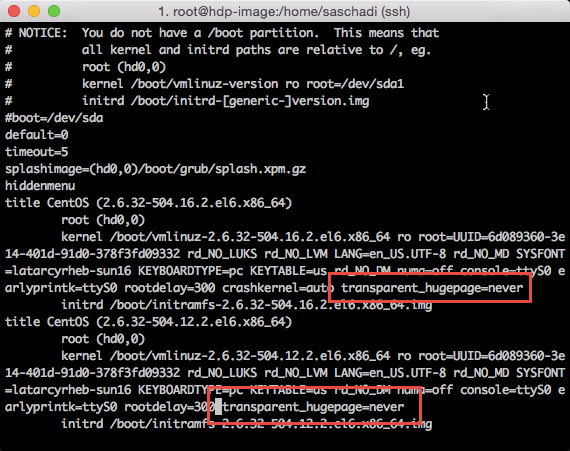
Hierzu muss man 2 kleinere Änderungen in der /etc/grub.conf vornehmen und bei den Kernel Aufrufen den Parameter »transparent_hugepage=never« anhängen.
vi /etc/grub.conf
Netzwerk Konfiguration
Bei der Netzwerk Konfiguration habe ich zwei Änderungen vorgenommen.
Zum einen hab ich die IP v6 Unterstützung aktiviert, indem ich bei der /etc/sysconfig/network Konfigurationsdatei »NETWORKING_IPV6« auf »yes« gesetzt habe.
vi /etc/sysconfig/network
oder
echo 'NETWORKING_IPV6=yes' >> /etc/sysconfig/network
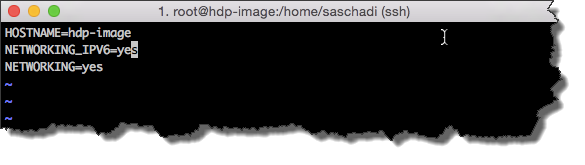
Außerdem habe ich die hosts-Datei bereits mit den entsprechenden Einträgen der zukünftigen Cluster-Knoten versehen.
Der in den »Azure Virtual Networks« integrierte DNS-Dienst verrichtet zwar hervorragend seinen Dienst, allerdings fehlt bei der Hadoop Installation ein »Fully Qualified Domain Name (FQDN)« für jeden Cluster-Knoten.
Deshalb habe ich die pragmatischen Schritt gewählt.
vi /etc/hosts
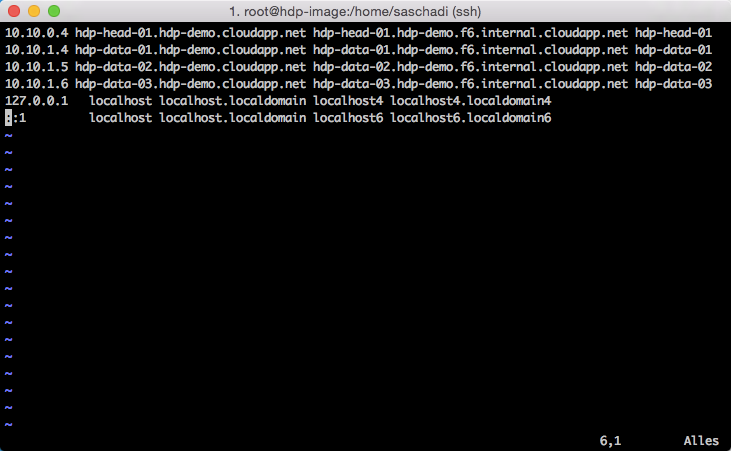 Die hierbei verwende Domain-Struktur ist komplett ausgedacht und setzt auf der Domain des Cloud-Service-Endpunkts auf.
Die hierbei verwende Domain-Struktur ist komplett ausgedacht und setzt auf der Domain des Cloud-Service-Endpunkts auf.
Über »hostname -f« läßt sich der interne FQDN anzeigen, welchen ich auch mit in die hosts-Datei übernommen habe.
| IP | FQDN | HOSTNAME |
|---|---|---|
| 10.10.0.4 | hdp-head-01.hdp-demo.cloudapp.net | hdp-head-01 |
| 10.10.1.4 | hdp-data-01.hdp-demo.cloudapp.net | hdp-data-01 |
| 10.10.1.5 | hdp-data-02.hdp-demo.cloudapp.net | hdp-data-02 |
| 10.10.1.6 | hdp-data-03.hdp-demo.cloudapp.net | hdp-data-03 |
Festplatte hinzufügen
Als letzten Punkt für das Basis-Image, füge ich noch eine zweite Festplatte hinzu, welche später als Datenplatte für das HDFS dienen soll.
Hierzu wechsel ich im Azure Management Portal in das Dashboard der Virtuellen Machine und wähle die Aktion »Attach empty disk« aus:
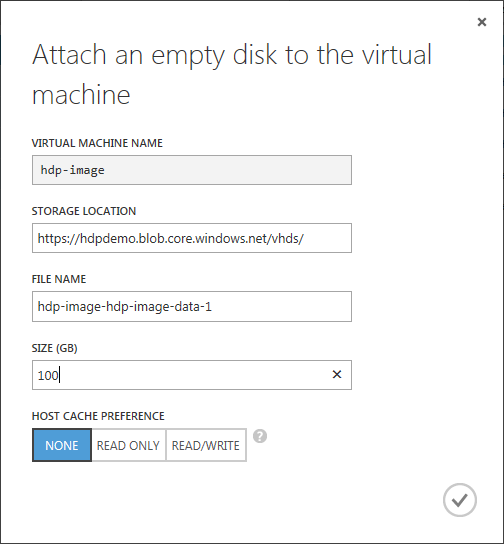 Im daraufhin erscheinenden Dialog wähle ich die entsprechende Plattengröße (in diesem Fall 100GB) aus und passe ggf. den Namen der VHD-Datei an.
Im daraufhin erscheinenden Dialog wähle ich die entsprechende Plattengröße (in diesem Fall 100GB) aus und passe ggf. den Namen der VHD-Datei an.
Anschließend wechsel ich wieder zur SSH-Konsole zurück.
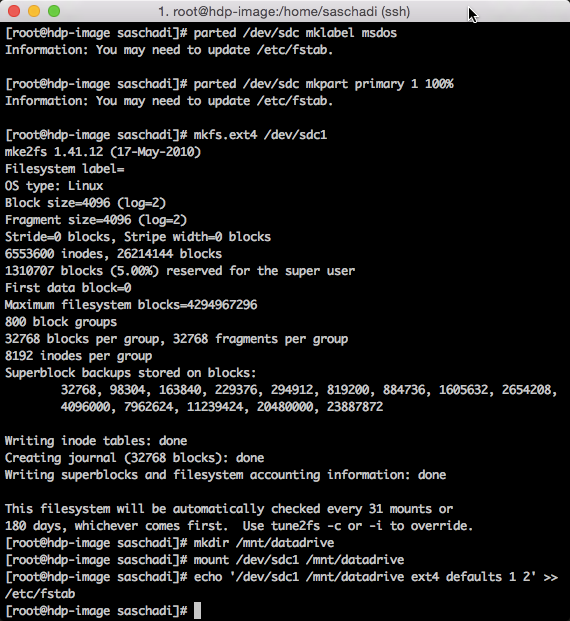
Dort partitioniere und formatiere ich die neue Festplatte, mounte diese als Verzeichnis /mnt/datadrive und passe die Konfigurationsdatei /etc/fstab entsprechend an, damit diese Veränderung auch nach einem Neustart zur Verfügung steht.
parted /dev/sdc mklabel msdos parted /dev/sdc mkpart primary 1 100% mkfs.ext4 /dev/sdc1 mkdir /mnt/datadrive mount /dev/sdc1 /mnt/datadrive echo '/dev/sdc1 /mnt/datadrive ext4 defaults 1 2' >> /etc/fstab
VM in ein Image umwandeln
Nachdem die Virtuelle Maschine soweit vorbereitet wurde, kann diese jetzt in ein Image umgewandelt werden.
Dazu verwende ich als Erstes den VM Agent, um in Linux alles zu entfernen, was eine Dublizierbarkeit behindern könnte.
waagent -deprovision
shutdown -h 0
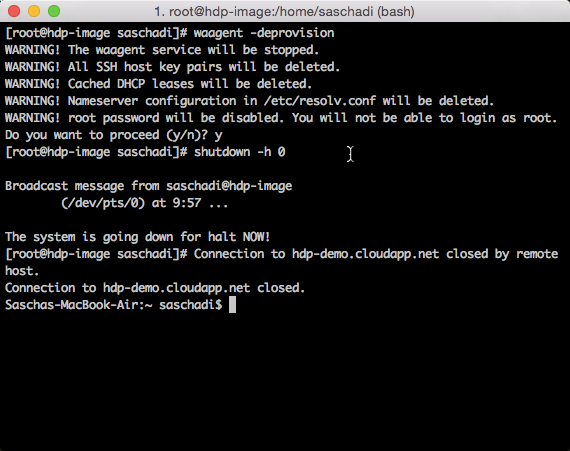
Anschließend kann ich die VM im Azure Management Portal herunterfahren…
… und in ein Image umwandeln.
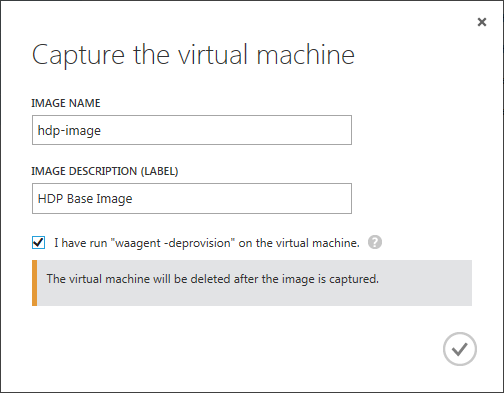 In dem Capture-Dialog gebe ich dem Image einen Namen, wie beispielsweise »hdp-image«, und setzte das Häkchen, dass der Deprovision-Vorgang durchgeführt worden ist.
In dem Capture-Dialog gebe ich dem Image einen Namen, wie beispielsweise »hdp-image«, und setzte das Häkchen, dass der Deprovision-Vorgang durchgeführt worden ist.
Wie geht’s weiter?
Nachdem jetzt das Basis-Image für die Cluster-Knoten erstellt wurde, wird im dritten Teil das eigentliche Hadoop on Linux-Cluster erzeugt.
