 Sascha Dittmann Über .NET, SQL Server und die Cloud
Sascha Dittmann Über .NET, SQL Server und die Cloud
 Vor kurzem benötigte ich ein Hadoop on Linux Test-Cluster, welches relativ nah an eine lokale Produktionsumgebung rankommen sollte. Somit fielen leider HDInsight (inkl. der Hadoop on Linux Preview), durch die Nutzung des Blob Storages aus.
Vor kurzem benötigte ich ein Hadoop on Linux Test-Cluster, welches relativ nah an eine lokale Produktionsumgebung rankommen sollte. Somit fielen leider HDInsight (inkl. der Hadoop on Linux Preview), durch die Nutzung des Blob Storages aus.
Grund genug, um einmal aufzuzeigen, wie man ein Hadoop on Linux Cluster mit Azure VMs aufsetzen kann.
Da das Ganze für einen einzelnen Blog Post etwas zu umfangreich ausfallen würde, möchte ich dies in folgende 3 Teile aufsplitten:
-
Vorbereitung der Azure Umgebung
(Storage Account, Cloud Service und Virtuelles Netzwerk) - Erstellen eines Basis-Images
- Erzeugen des Clusters
Storage Account & Cloud Service
Wie für die Virtuellen Maschinen in Azure üblich, benötigt man hierzu einen »Storage Account« für die VHD Dateien, sowie einen »Cloud Service« als Container und Endpunkt für die VMs.
Beides lässt sich zwar auch während des Erstellens der VMs erzeugen, allerdings finde ich zum Einen sprechende Namen für die jeweiligen Dienste sinnvoller und zum Anderen weiß man dann auch genau, was bzw. wofür etwas erstellt worden ist.
Beides lässt sich ganz einfach über das Azure Management Portal erstellen.
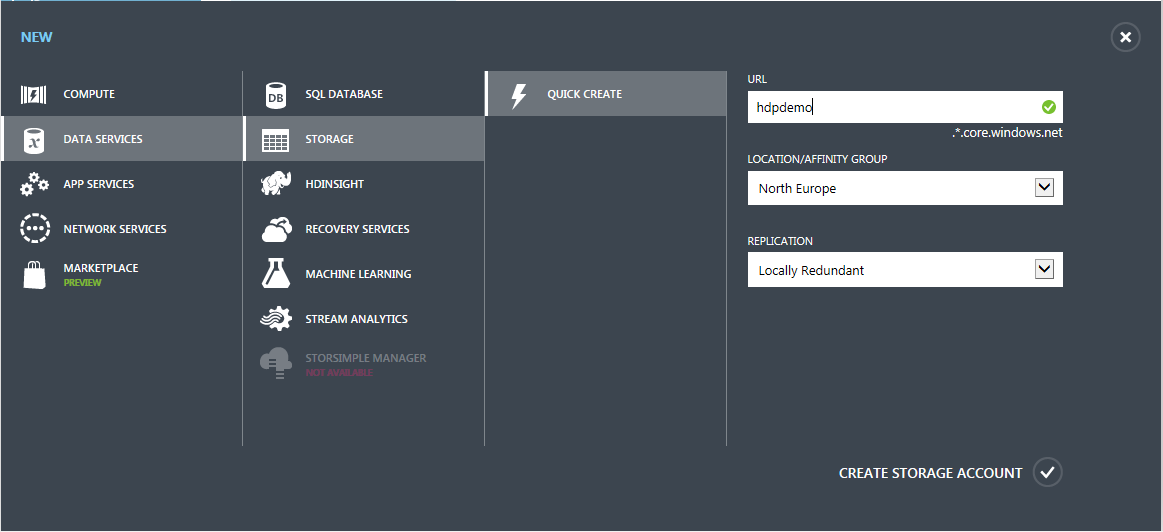 Für das Azure Storage Account geht man auf New -> Data Services -> Storage -> Quick Create und gibt dem Storage Account einen Namen.
Für das Azure Storage Account geht man auf New -> Data Services -> Storage -> Quick Create und gibt dem Storage Account einen Namen.
Außerdem sollte man noch das gewünschte Rechenzentrum, sowie den Replikationstyp, auswählen.
Für mein Test-Cluster langt die Replikation innerhalb des ausgewählten Rechenzentrums völlig aus, weshalb ich „Locally Redundant“ ausgewählt habe.
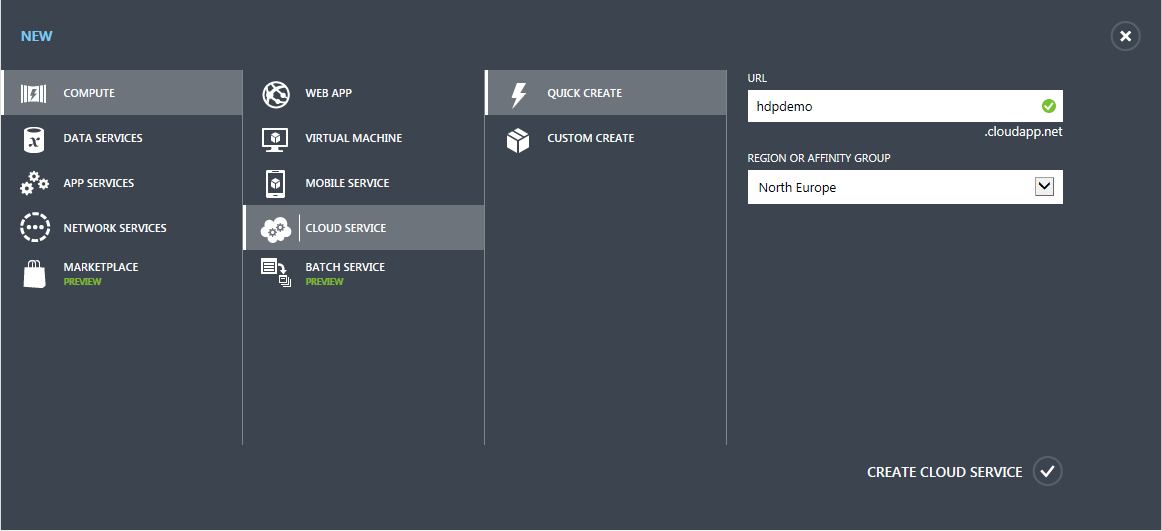 Auch der Cloud Service ist schnell erstellt.
Auch der Cloud Service ist schnell erstellt.
Hierzu wählt man New -> Compute -> Cloud Service -> Quick Create aus und gibt auch hier Name und das gleiche Rechenzentrum an.
Virtuelles Netzwerk
Nachdem man nun das Storage Account und die Cloud Service erstellt hat, kommt der etwas komplexere Teil an die Reihe – das Virtuelle Netzwerk.
Ich möchte innerhalb meines Virtuellen Netzwerks zwei Subnetze haben (eines für die Head-Nodes und eines für die Data-Nodes meines Hadoop Clusters), um erneut möglichst nah an die spätere Produktivumgebung heranzukommen.
Für etwaige Applikationen, die dieses Hadoop-Cluster benutzen, würde ich dann später ein weiteres Subnetz hinzufügen.
Soweit zum Plan – Kommen wir also zur Umsetzung…
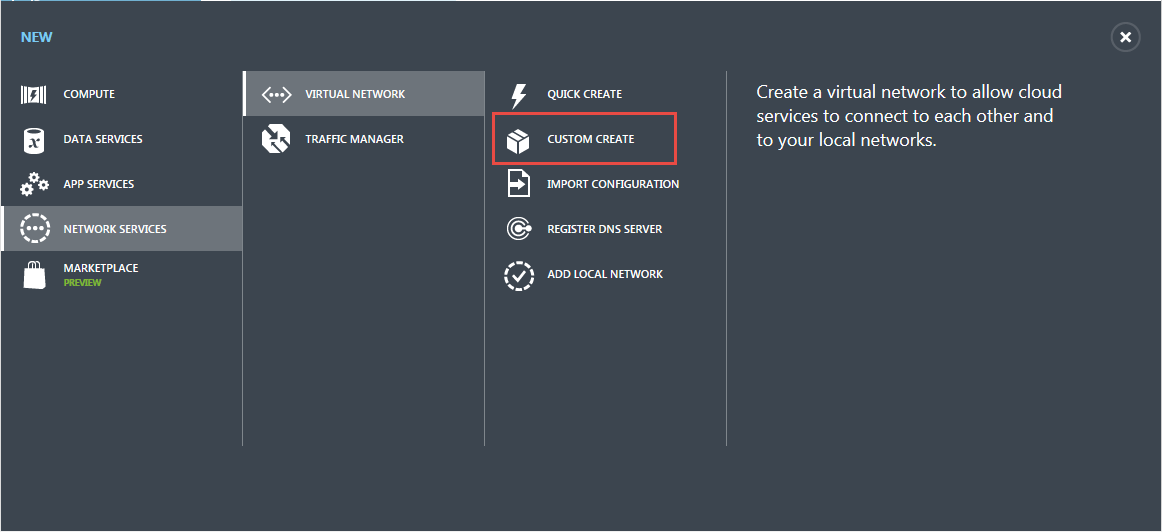 Für das neue Netzwerk wähle ich New -> Network Services -> Virtual Network -> Custom Create aus.
Für das neue Netzwerk wähle ich New -> Network Services -> Virtual Network -> Custom Create aus.
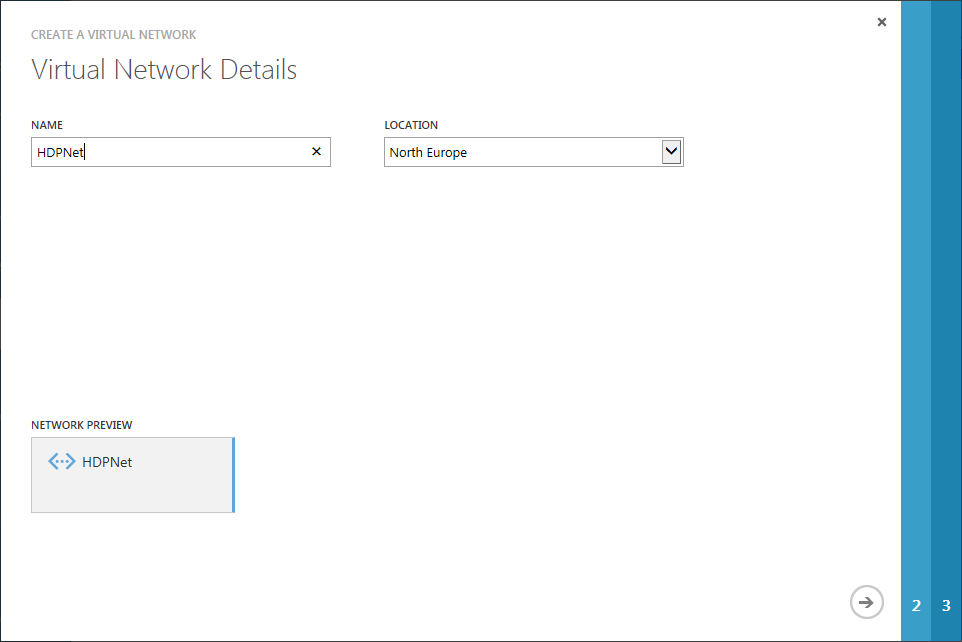 Im ersten Schritt des Assistenten-Dialogs gebe ich meinem neuen Netzwerk einen Namen und wähle erneut das gewünschte Rechenzentrum aus.
Im ersten Schritt des Assistenten-Dialogs gebe ich meinem neuen Netzwerk einen Namen und wähle erneut das gewünschte Rechenzentrum aus.
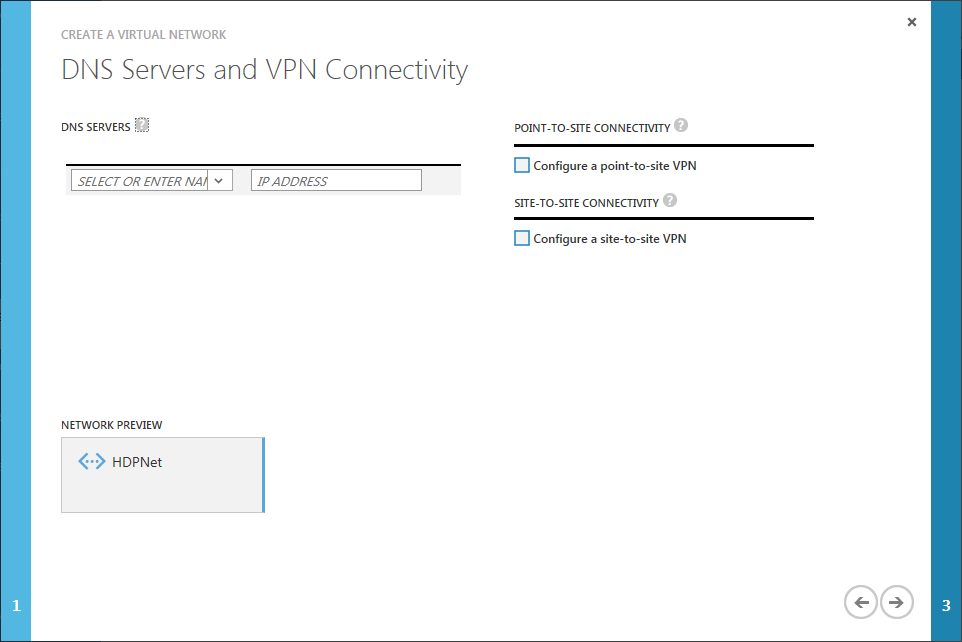 Den zweiten Schritt kann ich überspringen, da ich weder einen eigenen DNS Server angeben möchte, noch einen VPN Tunnel benötige.
Den zweiten Schritt kann ich überspringen, da ich weder einen eigenen DNS Server angeben möchte, noch einen VPN Tunnel benötige.
Der von Azure bereitgestellte DNS Dienst würde zwar vollkommen ausreichen, allerdings werde ich ohnehin für mein kleines Cluster die hosts-Datei entsprechend anpassen.
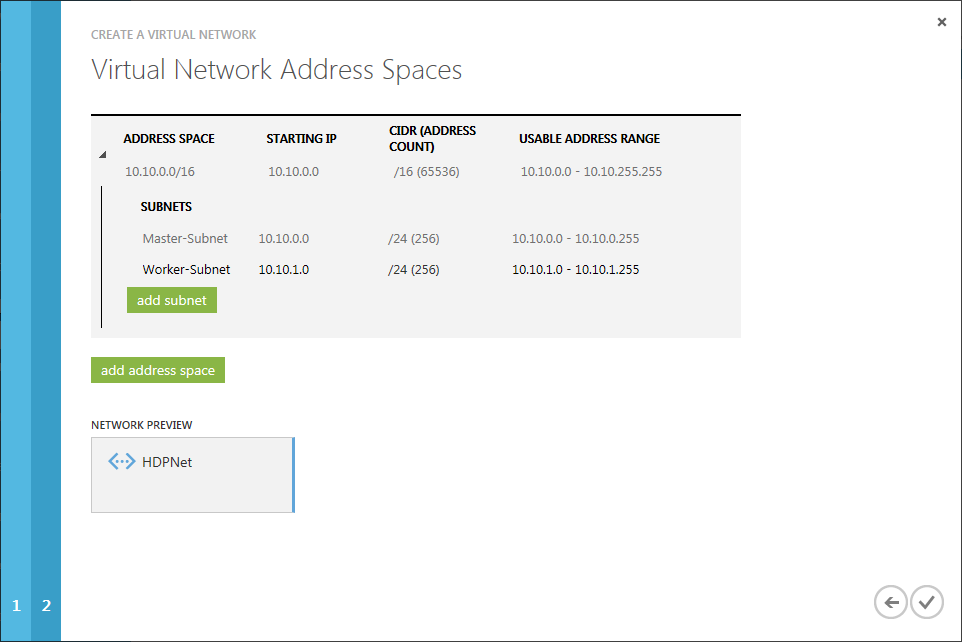 Im letzten Schritte gebe ich einen Adressraum (10.10.0.0/16), sowie die zwei Subnetze (Master-Subnet 10.10.0.0/24 und Worker-Subnet 10.10.1.0/24) an.
Im letzten Schritte gebe ich einen Adressraum (10.10.0.0/16), sowie die zwei Subnetze (Master-Subnet 10.10.0.0/24 und Worker-Subnet 10.10.1.0/24) an.
Wie geht’s weiter?
Im kommenden Teil erstelle ich ein Basis-Image für unsere Hadoop on Linux Cluster-Knoten.
