 Sascha Dittmann Über .NET, SQL Server und die Cloud
Sascha Dittmann Über .NET, SQL Server und die Cloud
 Nachdem ich in meinem Blog Post "Apache Hadoop für Windows Azure – MapReduce mit JavaScript" einen MapReduce-Algorithmus mit JavaScript vorgestellt hatte, möchte ich diesmal das Ganze mit Microsoft Bordmitteln umsetzen.
Nachdem ich in meinem Blog Post "Apache Hadoop für Windows Azure – MapReduce mit JavaScript" einen MapReduce-Algorithmus mit JavaScript vorgestellt hatte, möchte ich diesmal das Ganze mit Microsoft Bordmitteln umsetzen.
Auch hier kommt wieder die Developer Preview der Apache Hadoop-based Services for Windows Azure zum Einsatz.
Hadoop Streaming
MapReduce-Algorithmen lassen sich, dank der Streaming-Funktionalität des Apache Hadoop Frameworks, in jeder Programmiersprache umsetzen, die auf dem zu Grunde liegenden Betriebssystem ausführbar ist.
Hadoop Streaming wurde standardmäßig für Text-Datenströme ausgelegt, obwohl in der Version 0.21.0 auch Binärströme implementiert wurden.
Da also die Apache Hadoop-based Services for Windows Azure auf Windows 2008 Server Instanzen ausgeführt werde, wollte ich einmal die Umsetzung mit dem .NET Framework, genauer gesagt mit C#, ausprobieren.
Das Map Programm
Das Map Programm bekommt hierbei den Text-Datenstrom Zeile für Zeile übermittelt, und gibt, über seine Konsolenausgabe, die Ergebnis Schlüssel / Wert – Paare (durch ein Tab-Zeichen getrennt) zurück.
Als Beispiel greife ich erneut das Wörterzählen-Szenario, aus dem Blog Post "Apache Hadoop für Windows Azure – MapReduce mit JavaScript", auf.
Somit würde der C# Code des Map Programms wie folgt aussehen:
using System;
using System.Text.RegularExpressions;
namespace WordCountMapper
{
class Program
{
static void Main(string[] args)
{
string line;
var regex = new Regex("[a-zA-Z]+");
// Einlesen des Hadoop Datenstroms
while ((line = Console.ReadLine()) != null)
{
foreach (Match match in regex.Matches(line))
{
// Schreiben in den Hadoop Datenstrom
Console.WriteLine("{0}t1", match.Value.ToLower());
}
}
}
}
}
Das Reduce Programm
Beim Reduce Programm wird der zu schreibende Code nicht ganz so schön, wie bei meinem JavaScript Beispiel, da zwar vom Hadoop MapReduce Framework die Liste der Schlüssel / Wert – Paare vorsortiert wird, aber gemeinsamen Werte nicht wie gehabt in einem Array, sondern Zeile für Zeile übermittelt werden.
using System;
namespace WordCountReducer
{
class Program
{
static void Main(string[] args)
{
string line;
string prevWord = null;
int count = 0;
// Einlesen des Hadoop Datenstroms
while ((line = Console.ReadLine()) != null)
{
if (!line.Contains("t"))
continue;
var word = line.Split('t')[0];
var cnt = Convert.ToInt32(line.Split('t')[1]);
if (prevWord != word)
{
if (prevWord != null)
Console.WriteLine("{0}t{1}", prevWord, count);
prevWord = word;
count = cnt;
}
else
count += cnt;
}
Console.WriteLine("{0}t{1}", prevWord, count);
}
}
}
Ausführen des MapReduce-Algorithmus
Die Vorbereitungen
Um den in C# entwickelten MapReduce-Algorithmus ausführen zu können, müssen als Erstes die kompilierten Konsolenapplikationen in das Hadoop Distributed File System (HDFS) übertragen werden.
Auch hier bietet sich wieder die Interaktive JavaScript Konsole an:
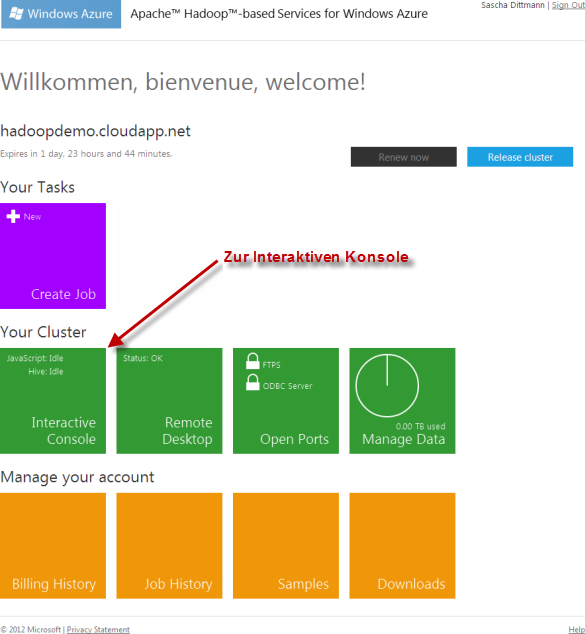
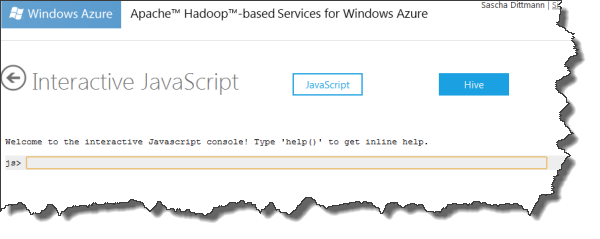
Für das spätere Wiederfinden der Assemblies, bieten sich absolute Pfadangaben, wie z.B. /examples/apps/WordCountMapper.exe, beim Upload an:
js> fs.put() File uploaded.
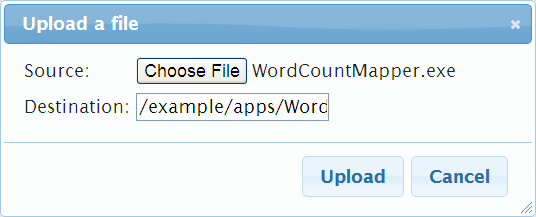
Dann noch eine kurze Kontrolle, ob alles erfolgreich in Hadoop gelandet ist:
js> #ls texte Found 17 items -rw-r--r-- 3 Sascha supergroup 366 2012-04-26 16:48 /user/Sascha/texte/Faust_01.txt -rw-r--r-- 3 Sascha supergroup 351 2012-04-26 16:48 /user/Sascha/texte/Faust_02.txt -rw-r--r-- 3 Sascha supergroup 340 2012-04-26 16:48 /user/Sascha/texte/Faust_03.txt -rw-r--r-- 3 Sascha supergroup 358 2012-04-26 16:48 /user/Sascha/texte/Faust_04.txt -rw-r--r-- 3 Sascha supergroup 1071 2012-04-26 16:48 /user/Sascha/texte/Faust_05.txt -rw-r--r-- 3 Sascha supergroup 335 2012-04-26 16:48 /user/Sascha/texte/Faust_06.txt -rw-r--r-- 3 Sascha supergroup 353 2012-04-26 16:48 /user/Sascha/texte/Faust_07.txt -rw-r--r-- 3 Sascha supergroup 583 2012-04-26 16:49 /user/Sascha/texte/Faust_08.txt -rw-r--r-- 3 Sascha supergroup 659 2012-04-26 16:49 /user/Sascha/texte/Faust_09.txt -rw-r--r-- 3 Sascha supergroup 170 2012-04-26 16:49 /user/Sascha/texte/Faust_10.txt -rw-r--r-- 3 Sascha supergroup 1056 2012-04-26 16:49 /user/Sascha/texte/Faust_11.txt -rw-r--r-- 3 Sascha supergroup 995 2012-04-26 16:49 /user/Sascha/texte/Faust_12.txt -rw-r--r-- 3 Sascha supergroup 1128 2012-04-26 16:49 /user/Sascha/texte/Faust_13.txt -rw-r--r-- 3 Sascha supergroup 489 2012-04-26 16:49 /user/Sascha/texte/Faust_14.txt -rw-r--r-- 3 Sascha supergroup 609 2012-04-26 16:49 /user/Sascha/texte/Faust_15.txt -rw-r--r-- 3 Sascha supergroup 611 2012-04-26 16:49 /user/Sascha/texte/Faust_16.txt -rw-r--r-- 3 Sascha supergroup 444 2012-04-26 16:49 /user/Sascha/texte/Faust_17.txt js> #ls /example/apps Found 2 items -rw-r--r-- 3 Sascha supergroup 5120 2012-04-26 16:46 /example/apps/WordCountMapper.exe -rw-r--r-- 3 Sascha supergroup 5120 2012-04-26 16:46 /example/apps/WordCountReducer.exe
Bestimmen der NameNode IP Adresse
Um die hochgeladenen Dateien im HDFS eindeutig angeben zu können, benötigen wir noch die IP Adresse des HDFS Verzeichnisservers, genauer gesagt die des HDFS Name-Nodes.
Eine Einführung in den Aufbau und die Funktionsweise des HDFS werde ich in einem der kommenden Blog Post nachreichen.
Hierzu verbinden wir uns am Besten mit dem Name-Node-Server via Remote Desktop Connection:
Dieser enthält die Hadoop Konfigurationsdateien unter C:Appsdistconf.
Die für uns interessante Konfigurationsdatei ist die core-site.xml.
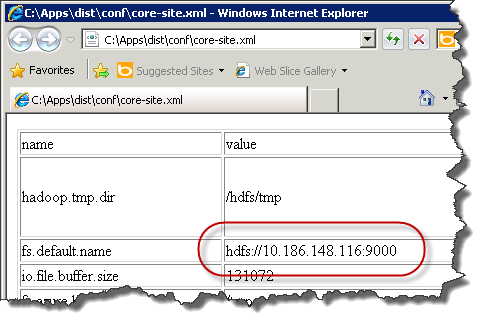
Diese enthält u.a. die fs.default.name Einstellung:
Ausführen des MapReduce Jobs
Nachdem nun alle Vorbereitungen abgeschlossen sind, kann via JavaScript Konsole der Job gestartet werden:
js> runJar('apps/hadoop-streaming.jar',
'-files "hdfs://10.186.148.116:9000/example/apps/WordCountMapper.exe,
hdfs://10.186.148.116:9000/example/apps/WordCountReducer.exe"
-mapper "WordCountMapper.exe" -reducer "WordCountReducer.exe"
-input "texte" -output "Woerter"')
Das MapReduce Protokoll
Das dabei entstehende Log, sieht wie folgt aus:
packageJobJar: [] [/C:/Apps/dist/lib/hadoop-streaming.jar] D:UsersSaschaAppDataLocalTempstreamjob1630339583880296337.jar tmpDir=null 12/04/26 17:18:06 INFO mapred.FileInputFormat: Total input paths to process : 17 12/04/26 17:18:08 INFO streaming.StreamJob: getLocalDirs(): [/hdfs/mapred/local] 12/04/26 17:18:08 INFO streaming.StreamJob: Running job: job_201204261607_0002 12/04/26 17:18:08 INFO streaming.StreamJob: To kill this job, run: 12/04/26 17:18:08 INFO streaming.StreamJob: C:Appsdist/bin/hadoop job -Dmapred.job.tracker=10.186.148.116:9010 -kill job_201204261607_0002 12/04/26 17:18:08 INFO streaming.StreamJob: Tracking URL: http://10.186.148.116:50030/jobdetails.jsp?jobid=job_201204261607_0002 12/04/26 17:18:09 INFO streaming.StreamJob: map 0% reduce 0% 12/04/26 17:18:33 INFO streaming.StreamJob: map 18% reduce 0% 12/04/26 17:18:34 INFO streaming.StreamJob: map 82% reduce 0% 12/04/26 17:18:35 INFO streaming.StreamJob: map 100% reduce 0% 12/04/26 17:18:54 INFO streaming.StreamJob: map 100% reduce 100% 12/04/26 17:19:06 INFO streaming.StreamJob: Job complete: job_201204261607_0002 12/04/26 17:19:06 INFO streaming.StreamJob: Output: Woerter
Das Ergebnis
Das Ergebnis kann, wie gewohnt, mit fs.read(…) angezeigt werden:
js> fs.read("Woerter")
ab 1
abendrot 1
aber 1
abgesponnen 1
ach 2
akkorden 1
alle 4
allein 1
allen 1
allenfalls 1
aller 1
allerliebste 1
allerschlimmste 1
alles 1
allgemeinen 1
als 2
alte 1
alten 1
alter 1
am 3
an 10
anblick 1
andern 1
angefochten 1
...
