 Sascha Dittmann Über .NET, SQL Server und die Cloud
Sascha Dittmann Über .NET, SQL Server und die Cloud
Im den ersten Postings der "SQL Server Closeup" Serie möchte ich einen Überblick über die Strukturen zur Speicherung von Daten in der SQL Server Storage Engine geben.
In diesem Teil werde ich mich dem Thema "Records" widmen.
In dieser Serie werde ich oft die englischen Originalbegriffe verwenden bzw. mit angeben, um Übersetzungsfehler zu vermeiden und auch konsistent mit den Meldungen des SQL Servers zu sein.
Ein paar Grundbegriffe vorab
Zum besseren Verständnis möchte ich einige Begrifflichkeiten stark vereinfacht erklären, die im weiteren Verlauf dieser Serie detailierter beschrieben werden.
Was ist ein Record
Ein Record ist eine physikalische Speichereinheit, welche mit einer Tabellen- oder Index-Zeile (engl. Row) verknüpft ist.
In der Literatur werden die Begriffe „Record“, „Row“ und „Slot“ oft synonym verwendet.
Was ist eine Page
Eine Page ist eine 8 Kilobyte große physikalische Speichereinheit, welche aus einem 96 Bytes großem Header, einem oder mehreren Records und einem Row Offset Array besteht.
Was ist eine Allocation Bitmap
Eine Allocation Bitmap ist eine Übersichtsseite (Page), die je nach Allocation Bitmap Typ in regelmäßigen Intervallen angelegt wird und unterschiedliche Informationen enthalten kann.
Welche Typen von Records gibt es
Data Records
-
Data Records speichern Zeilen eines Heap’s oder die Blattknoten eines Clustered Index
-
Als Heap wird eine Tabelle ohne Clustered Index bezeichnet.
Diese Tabelle enthält eine unstrukturierte Ansammlung von Zeilen. - Ein Clustered Index wird in Form eines Binärbaums gespeichert und gibt die Reihenfolge der Tabellenzeilen vor.
- Einem Non-Unique Clustered Index, also einem nicht eindeutigen Index, wird eine versteckte Spalte (engl. Column) hinzugefügt, um den Record eindeutig zu machen. Diese Spalte wird als ‚Uniquifier‘ bezeichnet.
-
Als Heap wird eine Tabelle ohne Clustered Index bezeichnet.
-
In einem Data Record werden immer alle Spalten einer Tabellenzeile gespeichert – entweder als Wert oder als Referenz.
-
Spalten die von einem LOB Datentyp (Large OBject) sind (text, ntext, image, oder die neuen Datentypen seit SQL Server 2005 – varchar(max), nvarchar(max), varbinary(max), xml) werden als Zeiger (engl. Pointer) innerhalb eines Data Records gespeichert. Diese Zeiger zeigen auf Text Records, welche auf einer anderen Page gespeichert werden.
Eine Ausnahme bilden Tabellen bei denen die Einstellungen für das ‚in-row‘ Speicherverhalten verändert wurden. Die Standardwerte sind hier ‚off-row‘ bei den alten Datentypen und ‚in-row‘ bei den neuen Datentypen. Bei dem ‚in-row‘ Speicherverhalten wird ein LOB Wert, der klein genug ist um in die Speichergrenzen eines Data Records zu passen, direkt im Data Record gespeichert. Dies bringt Geschwindigkeitsvorteile beim Lesen, da kein zusätzlicher Lesezugriff auf den Text Records erfolgen muss.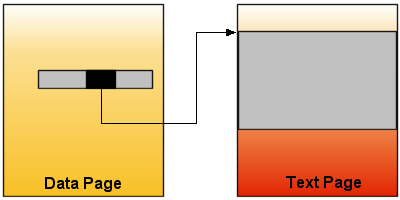 © Paul S. Randal, SQLskills.com
© Paul S. Randal, SQLskills.com - Seit dem SQL Server 2005, können Nicht-LOB Spalten mit variabler Länge, wie z.B. varchar oder sqlvariant, ‚off-row‘ gespeichert werden. Dies ist Teil des Row-Overflow-Features um Tabellen mit einer Zeilenbreite von über 8060 Bytes zu unterstützen. In so einem Fall werden die Spalten wie LOB Datentypen behandelt und auf einem Text Record ausgelagert.
-
Spalten die von einem LOB Datentyp (Large OBject) sind (text, ntext, image, oder die neuen Datentypen seit SQL Server 2005 – varchar(max), nvarchar(max), varbinary(max), xml) werden als Zeiger (engl. Pointer) innerhalb eines Data Records gespeichert. Diese Zeiger zeigen auf Text Records, welche auf einer anderen Page gespeichert werden.
- Es gibt einen Unterschied, wie Spalten eines Heap’s oder Clustered Index gespeichert werden. Dies werde ich in einem späteren Posting noch einmal aufgreifen.
Forwarded/Forwarding Records
- Technisch gesehen sind dies Data Records
- Sie kommen nur in Heap’s vor.
- Wenn ein Data Record durch Updates zu groß für seine Original Page wird, wird dieser auf eine andere Page verschoben. Diesen Data Record bezeichnet man dann als Forwarded Record. Anschliessend bekommt er einen Zeiger, welcher auf den Original Speicherplatz verweist. Dieser Zeiger wird benutzt, wenn der Data Record erneut verschoben werden muss, um den Forwarding Record zu aktualisieren. Somit werden Ketten von Lesezugriffen vermieden.
- Ein Forwarding Record wird als Ersatz für den Forwarded Record am alten Speicherplatz hinterlassen. Dieser beinhaltet einen Zeiger, der auf den neue Speicherplatz zeigt. Der Forwarding Record wird auch manchmal als Forwarding-Stub bezeichnet.
- Dieses Konstrukt soll vermeiden, das Non-Clustered Indizes zusätzlich aktualisiert werden müssen. Dies hat jedoch zur Folge, dass bei der Verwendung eines Non-Clustered Index nun zusätzliche Lesezugriffe durchgeführt werden müssen und bietet somit ein weiteres Argument bei der „Heap oder Clustered Index“ Entscheidungsfindung.
Index Records
- Es gibt zwei Arten von Index Records, welche sich nur anhand der gespeicherten Spalten unterscheiden
-
Zum Einen gibt es die Blattknoten (engl. Leaf-Level) – Index Records
-
Diese gibt es nur in Non-Clustered Indizes
Sie enthalten alle Non-Clustered Index Schlüsselspalten plus …- … einen Link zur passenden Tabellenzeile im Heap oder Clustered Index
- … jede Spalte die als INCLUDED bei der Erstellung des Non-Clustered Index mit angegeben wurde.
-
Diese gibt es nur in Non-Clustered Indizes
-
Zum Anderen gibt es die Nicht-Blattknoten (engl. Non-Leaf-Level) – Index Records
- Diese kommen in allen Indexarten oberhalb der Blattknoten vor.
- Sie enthalten Informationen, um die Storage Engine bei der Navigation durch den Binärbaum zu unterstützen. Dies ist der kleinste Schlüsselwert der untergeordneten Page sowie die Page ID (File ID + Page-In-File ID)
- Ich werde in einem späteren Posting genauer auf Indizes eingehen.
- Seit dem SQL Server 2005 können Non-Clustered Index Records auch LOB Datentypen enthalten (als INCLUDED Spalten). Diese werden wie bei den Data Records behandelt. Auch das Row-Overflow-Features ist hier wieder zu finden (siehe Data Records).
Text Records
- Text Records können Daten von LOB Datentypen, welche nicht ‚in-row‘ gespeichert wurden, sowie Datentypen mit variabler Länge, welche durch das Row-Overflow-Features ausgelagert wurden, enthalten
-
Es gibt zwei Arten von Text Records
- Text Records die Daten kleiner als 8 Kilobytes enthalten
- Text Records die einen unstrukturierten Baum bilden, um Daten größer als 8 Kilobytes zu speichern.
Versioned Data-, Index- und Text-Records
- Versioned Data-, Index- und Text-Records werden von Funktionen erstellt die das Versionierungssystem der Storage Engine nutzen, wie z.B. Online-Index Operationen, Spapshot Isolation, DML Trigger.
- Hierzu werden Versionen der alten Records (Updated/Deleted Records) im Version-Store in der tempdb Datenbank gespeichert.
-
Die Records die den aktuellen Stand enthalten werden um 14 Bytes erweitert
- Diese 14 Bytes enthalten einen Zeitstempel (engl. Timestamp), wann Versionierung durchgeführt wurde, plus einen Zeiger auf den Vorgänger-Record im Version-Store
- Diese 14 Bytes können zu Page Splits in Indizes bzw. Forwarding Records in Heaps führen
- Ein Lesevorgang einer anderen Abfrage muss ggf. eine Kette an Versioned Records durchforsten, um die Richtige Version zu erhalten.
- Das Versionierungssystem kann zu Platz- und Performanceproblemen der tempdb Daten führen.
Ghost Data-, Index- und Text-Records
- Ghost Data-, Index- und Text-Records können Clustered Index Data Records, alle Arten von Index Records und alle Arten von Text Records werden.
- Heap Data Records können nur zu Ghost Data Records werden, wenn eine Versionierung nötig ist.
- Ghost Records sind Records die logisch aber noch nicht physisch gelöscht worden sind. Ähnlich wie beim Dateisystem, werden diese Records nur als gelöscht markiert nicht jedoch direkt gelöscht.
- Nachdem die Transaction, die die Records als Ghost markiert hat, committed worden ist, kann ein asynchroner Hintergrundprozess – der Ghost Cleanup Task – die Records physikalisch löschen.
-
Wie wird der Ghost Cleanup Task auf die zu löschenden Records aufmerksam?
- Der Ghost Cleanup Task prüft alle 10 Sekunden (alle 5 Sekunden beim SQL Server 2005 und früheren Versionen) ob Aufgaben in seiner Warteschlange (engl. Queue) stehen
- Falls Ghost Records in der Queue stehen, löscht der Ghost Cleanup Task diese.
- Falls die Queue leer ist, durchsucht der Ghost Cleanup Task die Allocation Bitmaps der Datenbanken nach Pages mit Ghost Records.
-
Doch wie kommen Einträge in die Ghost Cleanup Task Queue?
- Falls die Storage Engine aus einem beliebigen Grund die Pages verarbeitet, auf denen sich Ghost Records befinden, werden Einträge in die Ghost Cleanup Task Queue geschrieben.
- Somit kann es eine Weile dauern, bis die zum löschen markierten Records wirklich gelöscht werden.
- Es kann auch passieren, dass Ghost Records wieder in Normale Records zurückkonvertiert werden, wenn vor dem physikalischen Löschvorgang ein exakt gleicher Record erstellt werden soll.
- Um den Platz wieder freizugeben, entfernt der Ghost Cleanup Task die Record Einsprungadresse, aus dem Row Offset Array am Ende der zugehörigen Page.
Wie ist ein Data Record aufgebaut
Fast alle Data Records im SQL Server haben den gleichen Aufbau mit ein paar Ausnahmen, wie z.B. Data Records für Sparse Columns oder Data Compression.
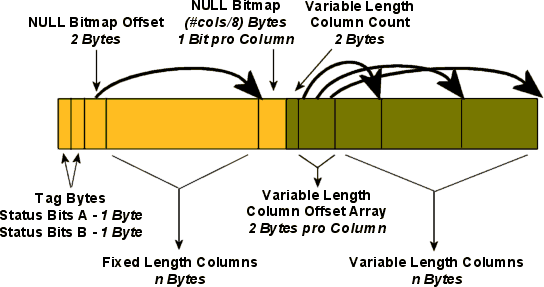
Ein „Standard“ Data Record ist wie folgt ausgebaut:
-
Tag Bytes – Status Bits A
- Bit 0 dient zur Versionierung und enthält in SQL Server 2008 immer eine 0
-
Bit 1 bis 3 definieren den Typ des Records
Als 3-Bit-Wert gesehen steht für folgendes:- 0 = Primary Record bzw. Data Record
- 1 = Forwarded Record
- 2 = Forwarding Record
- 3 = Index Record
- 4 = Text Record
- 5 = Ghost Index Record
- 6 = Ghost Data Record
-
7 = Ghost Version Record
Ein Sonderfall, den ich ggf. in einem späteren Posting aufgreifen werde.
-
Bit 4 gibt an, ob eine NULL Bitmap existiert.
Im SQL Server 2008 ist dies immer der Fall, auch wenn keine NULLs erlaubt wurden. - Bit 5 gibt an, ob eine Datentypen mit variabler Länge verwendet wurden.
- Bit 6 gibt an, ob Versionierungsinformationen enthalten sind. (siehe Versioned Records)
- Bit 7 wird nicht benutzt
-
Tag Bytes – Status Bits B
- Hier wird nur 1 Bit genutzt, welches anzeigt ob es sich um ein Ghost Forwarded Record handelt.
- Gefolgt von den Tag Bytes werden 2 Bytes genutzt, um die Länge des Bereichs für die nicht-variablen Spalten zu definieren.
- Dann kommen die Daten für die nicht-variablen Spalten (engl. Fixed Length Columns) gefolgt von 1 Bit pro Spalte welches bestimmt ob eine Spalte auf NULL gesetzt ist.
-
Falls keine Datentypen mir variabler Länge verwendet wurden, endet der Record hier.
Ansonsten wird in 2 Bytes die Anzahl der variablen Spalten angegeben. - Dann kommt ein Array, das die benutze Länge jeder variablen Spalte angibt (2 Bytes pro Spalte) gefolgt von den Daten der variablen Spalten
Egal in welcher Reihenfolge variable- und nicht-variable Spalte bei der Tabellendefinition angegeben werden, der SQL Server wird diese immer, wie oben beschrieben, aufteilen.
Einen kleinen Geschwindigkeitsvorteil könnte man ggf. dadurch erzielen, indem man variable Spalten, die mit hoher Wahrscheinlichkeit NULL sind, ans Ende der Tabellendefinition packt.
Kommende Themen
Der erste Grundstein für die Persistenz Strukturen wurde mit diesem Posting gelegt.
In den folgenden Postings werde ich den Überblick durch Pages, Extents sowie Allocation Bitmaps komplettieren dicht gefolgt von Beispielen, wie diese Strukturen am "Offenen Herzen" des SQL Servers aussehen.
Nach der vielen Theorie, soll auch das Coding nicht zu kurz kommen.
Quellen: SQLskills.com und Microsoft® SQL Server® 2008 Internals (ISBN-10: 0735626243)
